

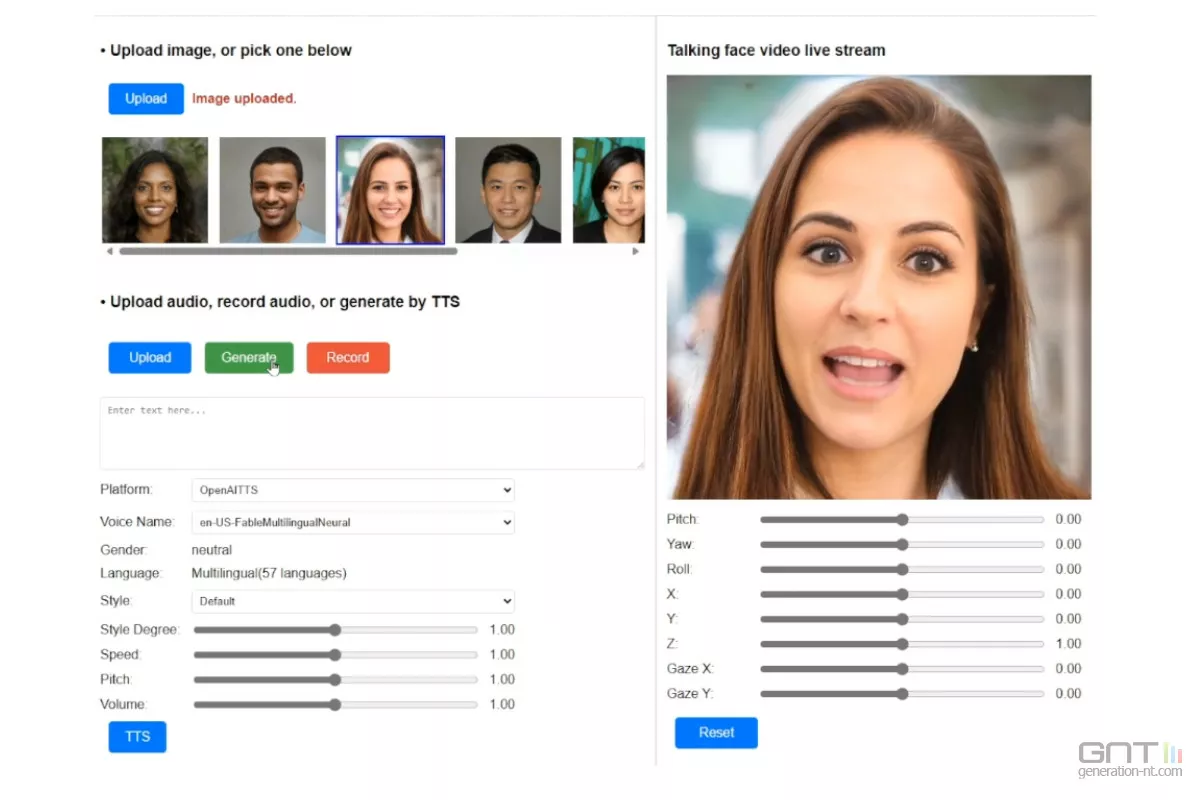
À partir d'une seule photo de portrait et d'un fichier audio existant, un modèle d'IA de Microsoft Research Asia est capable de générer une vidéo d'un visage qui s'anime et parle. Le résultat est voulu très réaliste pour les expressions faciales et la synchronisation labiale, ainsi que les mouvements de la tête.
Le modèle d'IA est dénommé VASA-1 et pour un framework éponyme signifiant Visual Affective Skills Animator. Dans une publication scientifique, Microsoft revendique plusieurs innovations et une méthode nettement plus performante que les méthodes précédentes.
" Notre méthode offre non seulement une qualité vidéo élevée avec une dynamique réaliste du visage et de la tête, mais prend également en charge la génération de vidéos d'une définition de 512 x 512 pixels jusqu'à 40 images par seconde avec une latence de départ négligeable. "
Une IA générative et une grande responsabilité
Microsoft souligne des perspectives en matière d'engagements en temps réel avec des avatars réalistes qui émulent les comportements conversationnels humains. Pour autant, il n'est pas encore question de proposer un quelconque produit ou des API, ni même une démo.
Il ne s'agit évidemment pas d'usurper l'identité d'une personne réelle de façon abusive, mais ce risque d'usurpation est plausible avec une telle technologie. De quoi mettre en avant une prudence légitime et une démarche responsable du développement de l'IA.
Par ailleurs, les vidéos générées contiennent pour le moment des artefacts identifiables et les chercheurs de Microsoft reconnaissent qu'un fossé reste à combler dans le but d'atteindre l'authenticité de vidéos réelles.
Des exemples tout de même bluffants
Le modèle VASA-1 a été entraîné sur le jeu de données publiques VoxCeleb2. Il constitue un ensemble de clips vidéo animés de paroles humaines. Plus d'un million de déclarations de plusieurs milliers de célébrités proviennent de vidéos mises en ligne sur YouTube.
Microsoft propose plusieurs exemples de vidéos obtenues grâce à VASA-1. Les photos utilisées par le modèle d'IA ont elles-mêmes été générées par d'autres outils d'IA (StyleGAN2 ou DALL·E-3). " Toutes les images de portraits sur la page sont des identités virtuelles et inexistantes ", peut-on lire. Il y a cependant une exception pour Mona Lisa.
Le résultat exposé est spectaculaire. Comme précédemment évoqué, il demeure néanmoins imparfait et l'intervention d'une IA est trahie. Des curiosités résident au niveau des dents quand la bouche est particulièrement ouverte, ou encore pour des saccades dans des mouvements.
